2023-12-05 22:00:00-0400
双人零和博弈 (two-player zero-sum game) 是指两个玩家的收益之和为零的博弈,是一种确定性的、双人、轮流、完全可观测的零和博弈;零和意味着一方的收益等于另一方的损失,即一方的收益为正,另一方的收益为负,两者之和为零。
在博弈的形式化定义中,通常用移动 (move) 来代替动作 (action),用局面 (position) 来代替状态 (state),用玩家 (player) 来代替代理 (agent)。形式化定义一般需要以下几个要素:
博弈树 (game tree) 是一种树形结构,它的每个节点都是一个局面,每个节点的子节点都是该节点的所有可能移动的结果。博弈树的叶子节点是终止状态,博弈树的根节点是初始状态。博弈树的高度是博弈的回合数,博弈树的宽度是每个局面的可能移动数。
每个参与者都以最优策略行动,在每一步决策时都选择自身收益最大的动作,即
\[ \max\limits_{a \in Actions(S)} \text{Utility}(Result(S, a), P) \]
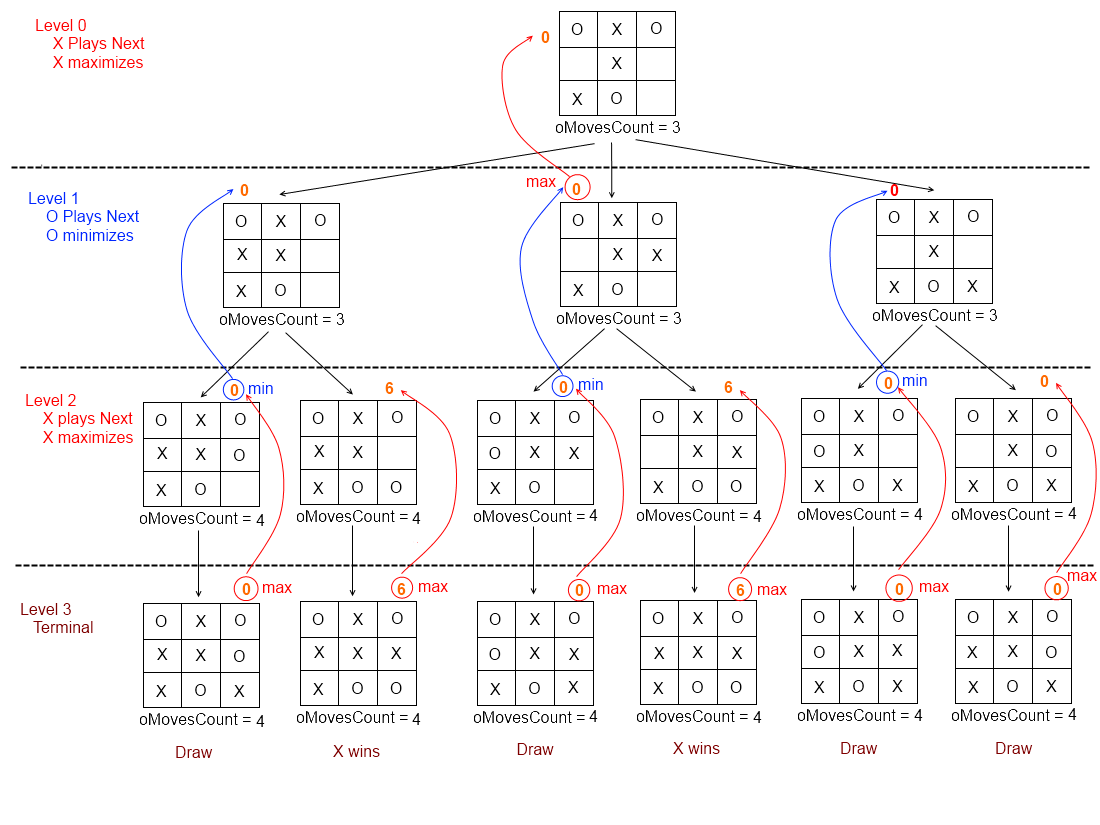
极小极大化搜索是一种递归式的搜索算法,它的思想是在每一步决策时,假设对手会采取最优策略,然后选择自身收益最大的动作。在每一步决策时,都会递归地调用极小极大化搜索,直到博弈结束。
def Minimax_Search(state) -> action:
player = To_Move(state) # 当前玩家
value, action = Max_Value(state, player) # 极小极大化搜索
return action # 返回最优动作
def Max_Value(state, player: int) -> (value, action):
if Is_Terminal(state): # 终止状态
return Utility(state, player), None # 返回收益,动作为空
value = -np.inf # 最大收益
action = None # 最优动作
for a in Actions(state): # 遍历所有可能的动作
next_state = Result(state, a) # 采取动作后的局面
next_player = To_Move(next_state) # 下一步的玩家
next_value, _ = Max_Value(next_state, next_player) # 递归调用极小极大化搜索
if next_value[player] > value: # 更新更大的收益和更优的动作
value = next_value[player] # 更新最大收益
action = a # 更新最优动作
return value, action # 返回最大收益和最优动作Minimax算法的时间复杂度是\(O(b^m)\),空间复杂度是\(O(bm)\),其中\(b\)是每个局面的平均分支因子/合法移动数量,\(m\)是树的深度。
考虑博弈树中某一层的一个节点,若玩家在同层的节点或更上层的节点中有更好的选择,那么该节点将不再会被访问,因为玩家不会选择它。Alpha-Beta 剪枝算法就是利用这一思想,减少极小极大化搜索的节点访问次数。在极小极大化搜索的基础上,我们需要为每位玩家维护一个已知的最大收益列表,在搜索过程中,如果某个节点的最大收益小于已知的最大收益,那么该节点将不再会被访问。
def Alpha_Beta_Search(state) -> action:
max_reached_value = [-np.inf] * num_players # 已知的最大收益列表
player = To_Move(state) # 当前玩家
value, action = Max_Value(state, player, max_reached_value) # 极小极大化搜索
return action # 返回最优动作
def Max_Value(state, player: int, max_reached_value: list) -> (value, action):
if Is_Terminal(state): # 终止状态
return Utility(state, player), None # 返回收益,动作为空
value = max_reached_value[player] # 已知的最大收益
action = None # 最优动作
for a in Actions(state): # 遍历所有可能的动作
next_state = Result(state, a) # 采取动作后的局面
next_player = To_Move(next_state) # 下一步的玩家
next_value, _ = Max_Value(next_state, next_player, max_reached_value) # 递归调用极小极大化搜索
if next_value[player] > value: # 更新更大的收益和更优的动作
value = next_value[player] # 更新最大收益
action = a # 更新最优动作
max_reached_value[player] = value # 更新已知的最大收益
else:
break # 剪枝
return value, action # 返回最大收益和最优动作考虑两种极端的\(\alpha\)-\(\beta\)剪枝情况:
这说明遍历顺序会影响\(\alpha\)-\(\beta\)剪枝的效果,因此我们需要对节点进行排序,使得效用值更大的节点先被遍历,效用值更小的节点后被遍历。
当节点效用未知时,排序显然是无法实现的;因此移动顺序适用于非终止节点可评价的搜索情况,如存在评价函数或迭代加深搜索,根据先前记录的节点价值就可以对节点进行排序。
博弈中的冗余路径主要指的是相同局面以不同顺序排列的路径,即换位 (transposition)。换位问题可以通过换位表解决。
极小化极大搜索不适用于枚举情况过多的博弈,即使使用\(\alpha\)-\(\beta\)剪枝和移动顺序,也无法在有限的时间内找到最优解。因此香农提出了A型和B型策略,A型策略是指在每一步决策时都考虑所有可能的移动,探索了宽而浅的部分;B型策略是指在每一步决策时都只考虑最好的几个移动,探索了窄而深的部分。
为了充分利用有限的计算资源和计算时间,使用评价函数 (evaluation function) 来代替效用函数,使用截断测试1 (cutoff test) 来代替终止状态的判断。评价函数是一种启发式函数,它可以对局面进行评估,但是它不一定能够准确地评估局面的价值。
对于终止状态,评价函数必须返回准确的效用值,即\(\text{Eval}(S, P) = \text{Utility}(S, P)\)。对于非终止状态,评价函数的值必须介于输和赢之间,即\(\text{Eval}(S, P) \in [\text{Utility}(\text{loss}, P), \text{Utility}(\text{win}, P)]\)。
几种常见的评价函数:
\[ \text{Eval}(S, P) = \sum\limits_{i=1}^{Count_{S_{T}}}\frac{Count_{S,S_{T_i}}}{\sum_{j=1}^{Count_{S_{T}}}{Count_{S,S_{T_j}}}}\text{Utility}(S_{T_i}, P) \]
\[ \text{Eval}(S, P) = \sum\limits_{i=1}^{n}w_i f_i(S) \]
截断搜索在合适的时候停止搜索,并返回评价函数的值。
截断搜索可以与深度限制搜索结合,当遇到终止状态或达到深度限制时,返回评价函数的值。
\[ \text{if IsCutoff}(S, d) \text{ then return Eval}(S, P) \]
\(\alpha\)-\(\beta\)搜索是A型策略,考虑了同一深度所有可能的移动;而前向剪枝属于B型策略,舍弃了那些看起来就很差的移动,尽管这些移动可能会导致更好的结果;前向剪枝使用束搜索,在每一层只考虑最好的几个移动,而不是所有可能的移动。
查表是指对已经搜索过的局面进行记录,当再次遇到相同的局面时,直接返回已知的结果。查表可以减少搜索的时间,但是会增加空间的开销。
蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 是一种不同于启发函数的估计方法,它使用多次完整模拟的平均最终效用来估计当前状态的价值。
\[ \text{Eval}(S, P) = \frac{1}{N} \sum\limits_{i=1}^{N} \text{Simulate}(S, P) \]
随机博弈是指环境中存在随机因素的博弈,即博弈的结果不仅取决于玩家的行动,还取决于环境的状态。随机博弈可以用随机博弈树 (stochastic game tree) 来表示,随机博弈树是一种扩展的博弈树,它包含了玩家层 (player layer) 和机会层 (chance layer)。
对于玩家层,每个节点表示一个状态,子节点表示可能的动作
\[ U(s) = \max\limits_{a \in A} Q(s,a) \]
对于机会层,每个节点表示父节点的状态和一个可能的动作,子节点表示可能转移到的所有状态
\[ Q(s,a) = \sum\limits_{s' \in S'} P(s' | s, a)U(s') \]
在随机博弈树中,玩家层对应的节点表示状态及最优动作,机会节点表示状态和可能的动作;从玩家层到机会层表示动作的选择,从机会层到玩家层表示状态的转移。
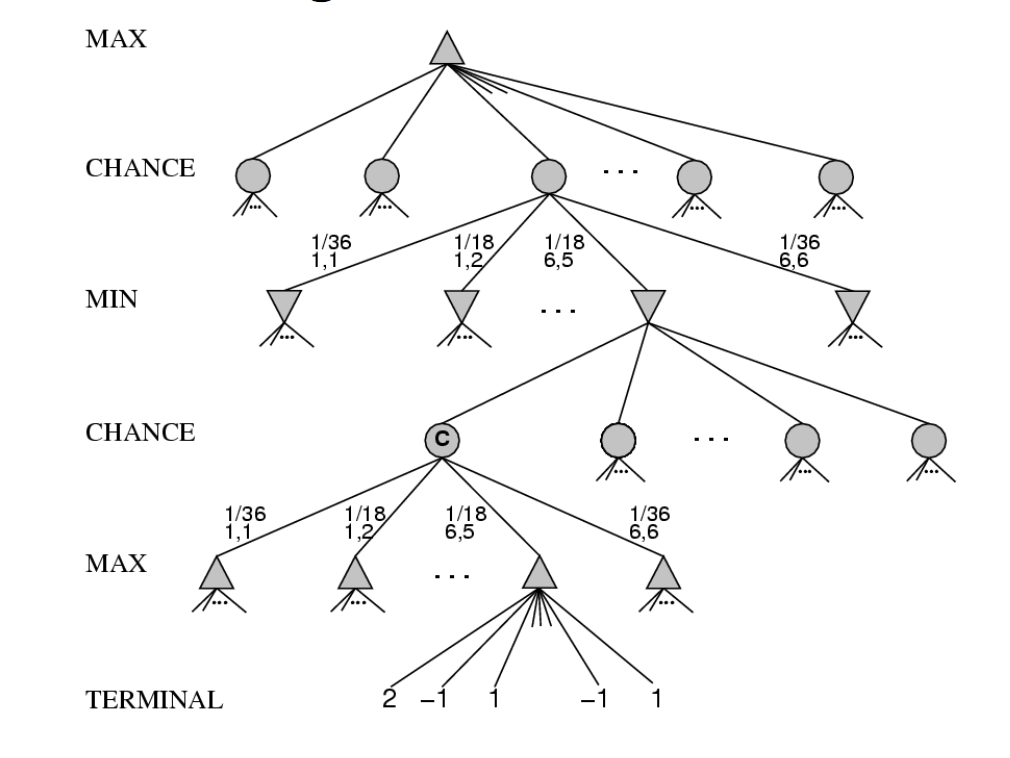
确定性极小极大化搜索扩展到随机博弈中变成包含机会节点的期望极小极大化搜索:
\[ \text{Expected-Minimax}(S, P) = \left \{ \begin{aligned} & \text{Utility}(S, P) & \text{if IsTerminal}(S) \\ & \max\limits_{a \in Actions(S)} \text{Expected-Minimax}(\text{Result}(S, a), P) & \text{if ToMove}(S) = P \\ & \sum\limits_{s' \in S'} \text{Probability}(s' | S, a) \text{Expected-Minimax}(s', P) & \text{otherwise} \end{aligned} \right. \]
def Expected_Minimax_Search(state) -> action:
player = To_Move(state) # 当前玩家
value, action = Max_Value(state, player) # 期望极小极大化搜索
return action # 返回最优动作
def Max_Value(state, player) -> (value, action):
if Is_Terminal(state): # 终止状态
return Utility(state, player), None # 返回收益,动作为空
value = -np.inf # 最大收益
action = None # 最优动作
for a in Actions(state): # 遍历所有可能的动作
next_value = Expected_Value(state, a, player) # 递归调用期望极小极大化搜索
if next_value[player] > value: # 更新更大的收益和更优的动作
value = next_value[player] # 更新最大收益
action = a # 更新最优动作
return value, action # 返回最大收益和最优动作
def Expected_Value(state, action, player) -> value:
value = 0 # 期望收益
for next_state in Result(state, action): # 遍历所有可能的状态
prob = Probability(state, action, next_state) # 转移到下一状态的概率
next_player = To_Move(next_state) # 下一步的玩家
next_value, _ = Max_Value(next_state, next_player) # 递归调用极小极大化搜索
value += prob * next_value[player] # 更新期望收益
return value # 返回期望收益纳什均衡 (Nash Equilibrium) 是指在博弈中,当满足特定条件时,任何一位玩家在改变自身策略而其他玩家保持策略不变时,都不会获得更好的收益。纳什均衡是一种稳定的策略,它可以用于解决部分可观测博弈。
\[ V_i(\pi_1^*, \pi_2^*, \cdots, \pi_i^*, \cdots, \pi_n^*) \geq V_i(\pi_1^*, \pi_2^*, \cdots, \pi_i, \cdots, \pi_n^*) \]
\(\alpha\)-\(\beta\)搜索使用启发函数估计价值,蒙特卡洛树搜索使用随机模拟平均价值,这两种方法都不是完美的,它们都有一定的局限性: